Ich liebe es, Fahrrad zu fahren und umso schmerzt es mich, dass in meinem geliebten Berliner Bezirk Weißensee, die Radwege-Infrastruktur so bescheiden ausgebaut ist. Auf meinem täglichen Weg zur Arbeit teile ich mir also die Bundesstraße mit LKWs, PKWs, Bussen und anderen Verkehrsteilnehmenden. Ein schweres Thema, vor allem wenn man sich vor Augen führt, wieviele Verkehrsteilnehmer in Berlin pro Jahr sterben. Nicht wenige durch abbiegende LKWs.
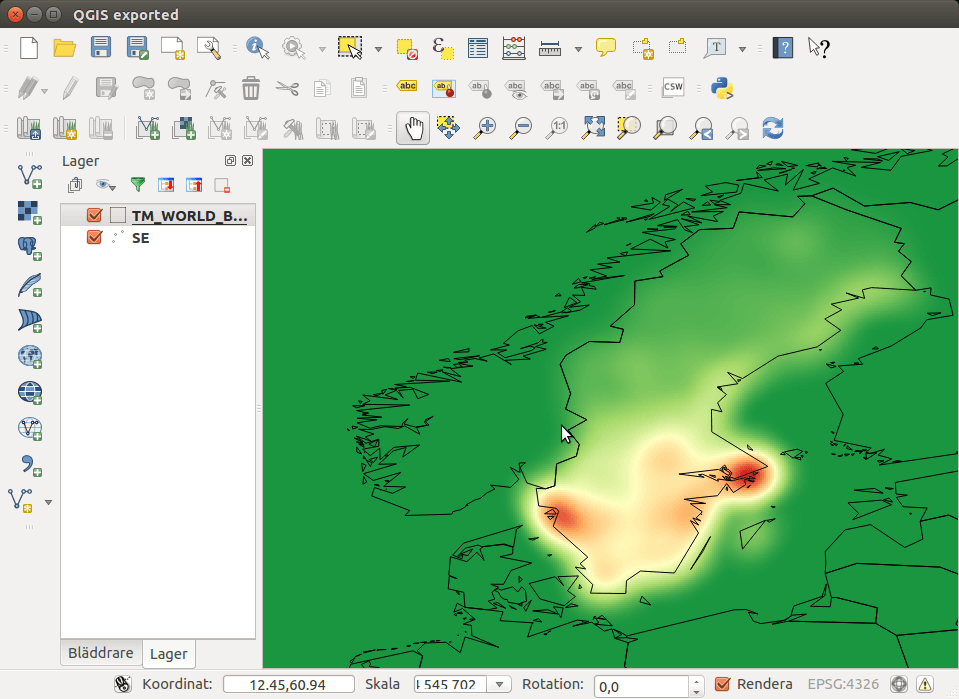
Kurz geärgert, hatte ich mir vorgenommen, einen Beschwerdebrief an die hiesige Senatorin und die lokal zuständige Stadträtin zu schreiben. Und da Bilder besser sind als tausend Worte: Ich brauchte eine Karte mit den Verkehrszahlen insbeseondere der LKW-Befahrungen auf meinem Straßenabschnitt.
- Disclaimer: Ich arbeite für Toll Collect, die Analyse war rein privat!
Was braucht es?
Die wesentlichen Daten kommen vom Bundesamt für Logistik und Mobilität aka BALM (ehemals BAG – Bundesamt für Güterverkehr). Für die Visiualisierungen benötigt man zum Einem die Straßenabschnitt (Geometriedaten) und die Befahrungszahlen. Leider ist der erstere Datensatz nur stark „abstrahiert“ vorhanden: Die Mauttabelle. Diese Tabelle enthält tausende sogenannte Abschnitte mit Start und Zielkoordinaten, Abschnittsnamen und den Längen.
Die Mauttabelle kann man aus dem etwas sperrigen Excel-Format mit einem einfachen Skript in ein schöneres geojson Format wandeln und somit in einem GIS leichter einlesen:
import pandas as pd
import json
df = pd.read_excel('2023-12-01_Mauttabelle.xlsx', skiprows=[0])
geojson = {
"type": "FeatureCollection",
"features": [
]
}
for index, row in df.iterrows():
geojson["features"].append(
{
"type": "Feature",
"properties": {"id": row["Abschnitts-ID"], "name": row["Von"] + " bis " + row["Nach"], "laenge": row["Länge"], "strasse": row["Bundesfernstraße"], "Bundesland": row["Bundesland"]},
"geometry": {
"coordinates": [
[
row["Länge Von"],
row["Breite Von"]
],
[
row["Länge Nach"],
row["Breite Nach"]
]
],
"type": "LineString"
}
}
)
with open('mauttabelle.geojson', 'w') as f:
json.dump(geojson, f, indent=4)Wer keine Lust zum coden hat, kann aber auch in der Mobilithek den entsprechenden Datensatz (check Disclaimer above) als WFS nutzen.
Die Befahrungsdaten pro Monat zu den jeweiligen Abschnitten gibt es hierbei auch beim BALM. Die Datei liegen in zwei Versionen vor. In der größeren mit Tarifparametern kann man sogar nach schweren und leichteren LKW selektieren. Wir konzentrieren uns auf die einfache Version mit 3MB:

Diese Datei enthält im Wesentlichen die Informationen pro Tarifabschnitt:
- Gesamtanzahl an Befahrungen
- Einnahmen pro Tarifabschnitt
- bezahlte Gesamtkilometer auf dem Tarifabschnitt
Für die notwendige Analyse konzentzriere ich mich auf die Anzahl der Gesamtbefahrungen.
Verarbeitung
Die Verarbeitung ist eigentlich kein rocket-science:
- Join
- Persistierung als performanteres Geopackage
- Selektion
- Visualiserung
Der Join auf dem Geojson wird per Abschnitts-id durchgeführt. Da ich aber das ganze nachvollziehbar und stabil gestalten möchte, machen wir den join mittels pandas in dem obigen skript. Zudem speichern wird das Ganze nun nicht mehr in geojson gespeichert, sondern wir nutzen das performantere Geopackage:
# Mautdaten
# by Riccardo Klinger
import pandas as pd
import geopandas as gpd
from pyproj import CRS
def main():
df = pd.read_excel('2023-12-01_Mauttabelle 2.xlsx', skiprows=[0])
df2 = pd.read_csv(
'Mautdaten_Bund_202312_ohne_Tarifparameter.csv', delimiter=";", encoding='unicode_escape')
print(df2)
df3 = pd.concat([df.set_index('Abschnitts-ID'), df2.set_index('Abschnitt-ID')],
axis=1, join='inner').reset_index()
geojson = {
"type": "FeatureCollection",
"features": [
]
}
print(df3)
for index, row in df3.iterrows():
geojson["features"].append(
{
"type": "Feature",
"properties": {"km": row["Summe mautpflichtige Kilometer"], "anzahl": row["Anzahl Abrechnungssätze"], "Einnahmen": row["Gebührensumme Ist"], "id": row["index"], "name": row["Von"] + " bis " + row["Nach"], "laenge": row["Länge"], "strasse": row["Bundesfernstraße"], "Bundesland": row["Bundesland"]},
"geometry": {
"coordinates": [
[
row["Länge Von"],
row["Breite Von"]
],
[
row["Länge Nach"],
row["Breite Nach"]
]
],
"type": "LineString"
}
}
)
gdf = gpd.GeoDataFrame.from_features(geojson['features'])
gdf.crs = CRS.from_epsg(4326)
# Write GeoDataFrame to GeoPackage
gdf.to_file('maut.gpkg', layer='MautdatenProAbschnitt', driver='GPKG')
if __name__ == '__main__':
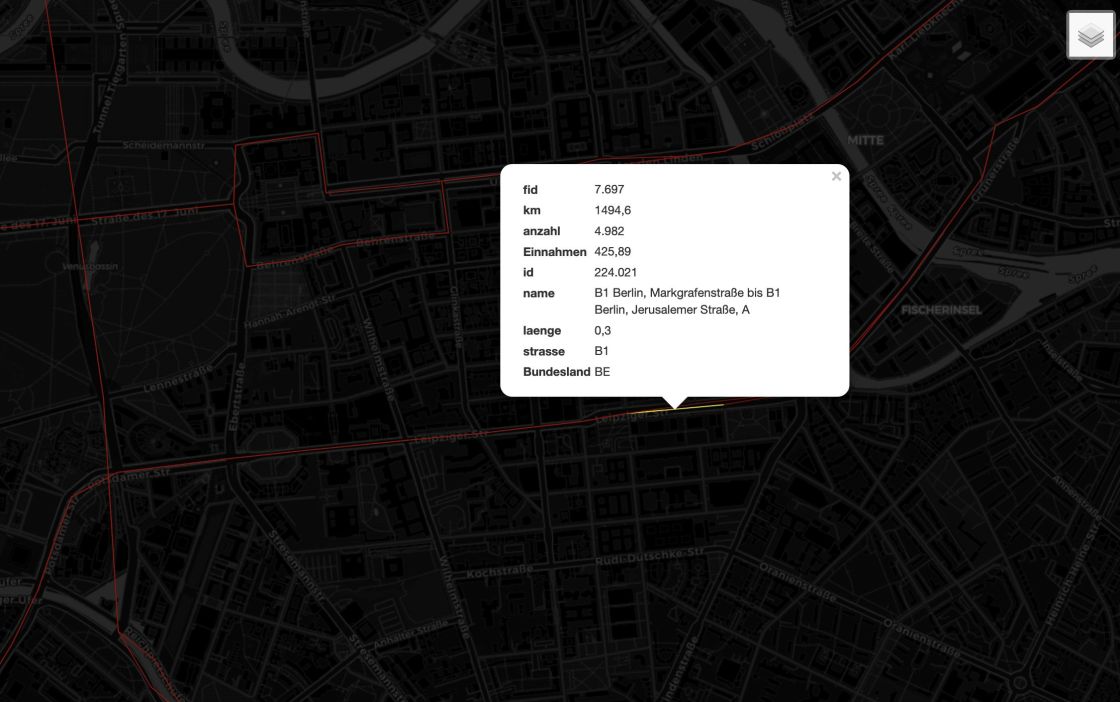
main()Das Ergebnis kann nun beliebig in QGIS ausgewertet werden und so zum Beispiel mit qgis2web in eine kleine interaktive Webanwendung verpackt werden.